
Opus 4.8 e os Dynamic Workflows: o que muda para quem analisa processos
Do analista solitário ao mutirão de subagentes: o que muda, na prática, para quem lê processo o dia inteiro.

Anthropic lançou hoje (28/05/2026) o Claude Opus 4.8 e, junto com ele, os “dynamic workflows” no Claude Code. Para além do hype de benchmark, há aqui duas mudanças que tocam diretamente no nosso dia a dia no Judiciário. Vou separar o que é marketing do que é, de fato, ferramenta de trabalho.
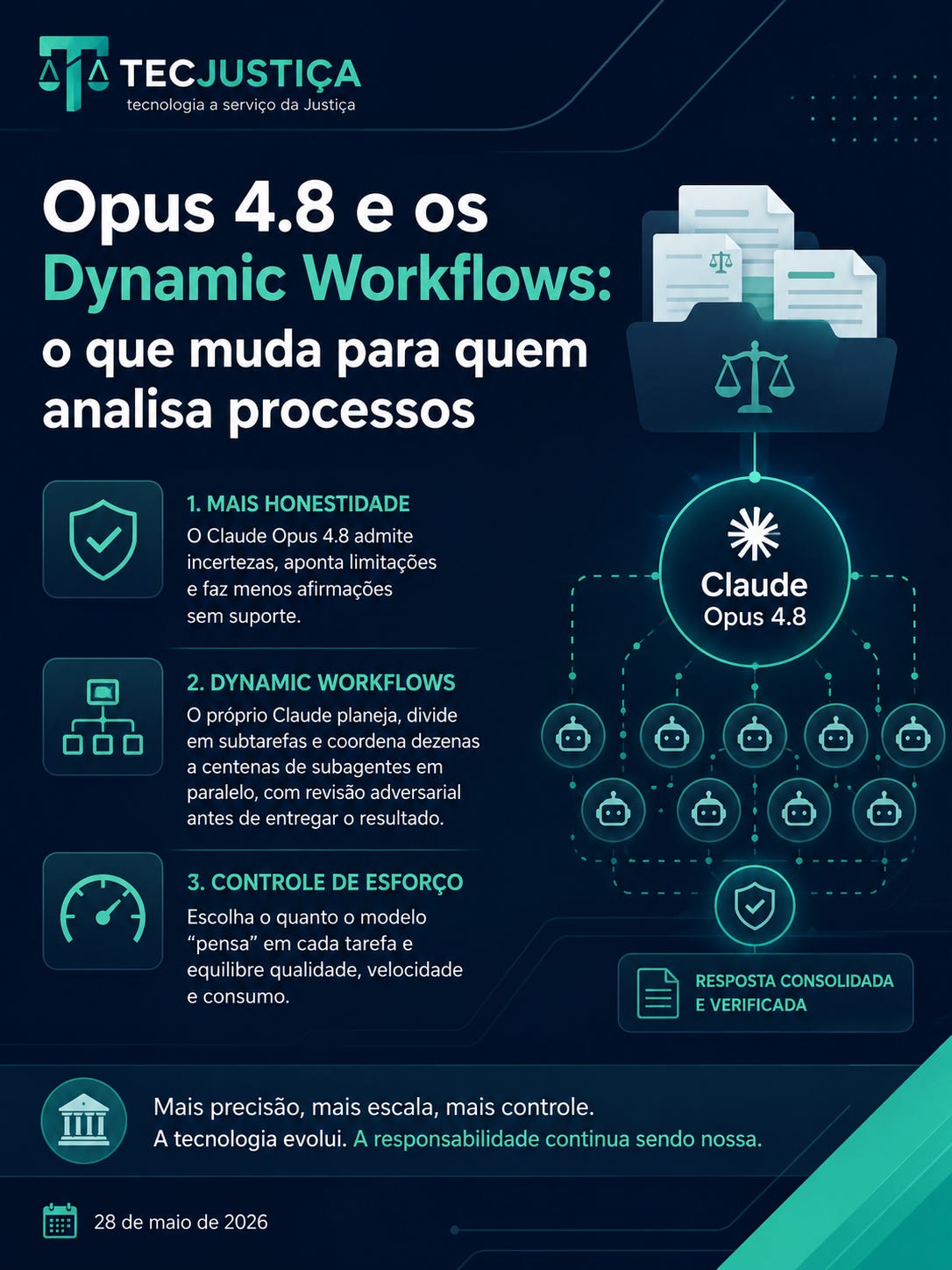
O resumo de 30 segundos
Saíram três coisas de uma vez:
Claude Opus 4.8 — nova versão do modelo principal, pelo mesmo preço do 4.7 (US$ 5 por milhão de tokens de entrada, US$ 25 de saída). Os ganhos foram em raciocínio jurídico, código, agentes de navegador e análise de documentos longos — mas o destaque, para nós, é outro: honestidade.
Dynamic workflows — um recurso do Claude Code (em research preview) que deixa o modelo escrever seus próprios scripts de orquestração e disparar dezenas a centenas de subagentes em paralelo, verificando o próprio trabalho antes de te entregar o resultado.
Controle de esforço (effort control) no Claude.ai e no Cowork — você passa a escolher o quanto o modelo “pensa” em cada tarefa, equilibrando qualidade, velocidade e consumo.
Vamos por partes, sempre amarrando na pergunta que importa: isso ajuda a analisar processo?
1. A feature mais subestimada do Opus 4.8: ele admite quando não sabe
Esse é o ponto que eu peço para você não pular.
O problema clássico de qualquer LLM aplicado ao Direito não é “errar uma vírgula”. É a confiança injustificada: o modelo afirma que encontrou um precedente, que o prazo prescricional já correu, que a tese se aplica — com a mesma cara séria de quando está certo e de quando está chutando. É exatamente assim que advogado é punido por citar acórdão que não existe.
A Anthropic afirma que o Opus 4.8 é cerca de quatro vezes menos propenso que o antecessor a deixar passar, sem aviso, uma falha no código que ele mesmo escreveu. (fonte oficial) E os testadores iniciais relataram que ele sinaliza incertezas com mais frequência e faz menos afirmações sem suporte. Um associado de investimentos da Bridgewater resumiu o que mais mudou: a tendência do modelo de apontar proativamente problemas nos próprios insumos e resultados — coisa que outros modelos deixavam para o usuário descobrir depois.
Analogia: imagine a diferença entre um estagiário que entrega a minuta dizendo “está pronto, pode assinar” e outro que entrega dizendo “olha, fiz a minuta, mas o cálculo da prescrição depende da data de citação que não localizei nos autos — confere antes de assinar”. O segundo dá mais trabalho de leitura? Não. Ele te dá menos trabalho de retrabalho. O Opus 4.8 está mais perto do segundo estagiário.
Para análise processual, isso é o que separa uma ferramenta de apoio de uma armadilha. Um relatório pré-audiência que diz “não consegui confirmar se houve resposta do executado — verifique o evento 42” vale mais do que um que inventa uma contestação que não está nos autos.
Os parceiros de área jurídica confirmam a direção: a CoCounsel (Thomson Reuters) relatou ganhos de consistência e qualidade de raciocínio sobre versões anteriores, e a Harvey registrou a maior pontuação já obtida no Legal Agent Benchmark deles, sendo o primeiro modelo a passar de 10% no padrão mais rígido (all-pass). São números de produtos comerciais, não do nosso contexto — mas a tendência de fundo (mais raciocínio jurídico, menos alucinação) é a que interessa.
2. Dynamic workflows: de “um analista” para “uma força-tarefa”
Aqui mora a mudança estrutural.
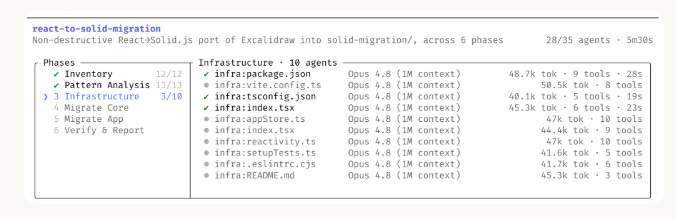
Até agora, quando você pedia ao Claude para analisar algo grande, ele fazia tudo em uma “passada” — um único raciocínio sequencial. Funciona bem para um processo. Começa a engasgar quando você pede “analise esses 80 processos da pauta” ou “varra todas as execuções fiscais da vara e me diga quais já prescreveram”.
Os dynamic workflows resolvem isso de um jeito diferente: o próprio Claude planeja a tarefa, quebra em subtarefas e dispara vários subagentes trabalhando em paralelo, cada um cuidando de um pedaço. Depois, outros agentes tentam refutar o que o primeiro grupo encontrou, e a execução fica iterando até as respostas convergirem. Só então o resultado volta consolidado para você. (fonte oficial)
Analogia jurídica: é a diferença entre um assessor lendo 80 processos sozinho, um por um, e um mutirão — em que cada servidor pega um lote, e ainda há um revisor conferindo o trabalho de cada um antes de bater o martelo. Os “agentes adversariais” são esse revisor: o segundo par de olhos que tenta achar o erro antes de você.
O caso emblemático que a Anthropic divulgou foi técnico (a reescrita do runtime Bun de uma linguagem para outra — ~750 mil linhas de código, com 99,8% dos testes passando, em 11 dias). Mas a forma do problema é a mesma que aparece no cartório: “percorra um volume enorme, item por item, sem deixar nada passar, e verifique cada achado”.
Onde isso encosta na análise processual
Pensando nas rotinas da vara e nas ferramentas do TecJustiça, os formatos que se beneficiam são:
Varredura de pauta inteira — gerar relatório pré-audiência de todos os processos designados para a semana, em vez de um a um. Casa direto com a skill de relatórios pré-audiência.
Auditoria em lote — “em todas as execuções fiscais da vara, identifique as que têm indício de prescrição intercorrente (art. 40 da LEF) e separe por marco interruptivo”. Cada subagente pega um processo; o revisor confere o cálculo do prazo.
Levantamento de dados estruturados — extrair endereços, partes, valores ou objetos de centenas de processos de uma vez (o tipo de coisa que a skill
relatorio-enderecos-processosjá faz para um, agora em escala).Trabalho crítico conferido duas vezes — uma minuta de decisão ou sentença em que o custo do erro é alto. Aqui o valor não está na velocidade, e sim no segundo agente tentando quebrar o argumento antes de você assinar.
Um alerta honesto (no espírito do próprio 4.8): dynamic workflows consomem muito mais tokens que uma sessão normal de Claude Code. A própria Anthropic recomenda começar por uma tarefa pequena e delimitada para sentir o consumo. E há um detalhe institucional importante: o recurso está disponível nos planos Max, Team e Enterprise (e via API), com Enterprise desligado por padrão no lançamento. Ou seja, não é algo que você simplesmente liga numa conta comum — exige planejamento de plano e de custo. Para nós, que pensamos o TecJustiça como ponte, isso reforça a tese: o ganho vem de orquestrar bem, não de torrar token.
3. Controle de esforço: a tecla que faltava para o custo fazer sentido
A terceira novidade é a mais discreta e, na prática diária, talvez a mais útil: o controle de esforço ao lado do seletor de modelo, no Claude.ai e no Cowork, disponível em todos os planos.
Você passa a escolher:
Esforço baixo → resposta rápida, consome menos a sua cota. Ideal para triagem, classificação, “esse processo é cível ou criminal?”, resumo de movimentação.
Esforço alto (padrão do 4.8) → o modelo pensa mais e mais fundo. Para análise de mérito, cálculo de prazo, redação de minuta.
Extra / Máximo → para tarefas difíceis e fluxos assíncronos longos.
Analogia: é como decidir se você manda o processo para o juízo de admissibilidade (triagem rápida) ou para análise de mérito (leitura cuidadosa). Nem todo ato precisa do mesmo esforço — e agora você não paga (em tempo e em cota) o preço da análise profunda quando só precisa de uma triagem.
Há ainda uma novidade voltada a quem desenvolve: a Messages API agora aceita entradas de system dentro do array de mensagens, o que permite atualizar as instruções do Claude no meio de uma tarefa — mudar permissões, orçamento de tokens ou contexto de ambiente — sem quebrar o cache de prompt. Para quem mantém harness próprio ou servidor MCP (caso do TecJustiça MCP Lite), isso abre caminho para agentes de longa duração que se reconfiguram durante a execução. Detalhe técnico, mas relevante para a próxima geração das nossas ferramentas.
O que eu, de fato, mudaria a partir de hoje
Sem exagero e sem fé cega no release:
Trocar para Opus 4.8 em análises sensíveis. O ganho de honestidade — sinalizar incerteza em vez de chutar — é exatamente o que reduz risco em parecer, relatório e minuta. Mesmo preço, então não há motivo para ficar no 4.7.
Tratar dynamic workflows como ferramenta de mutirão, não do dia a dia. Reserve para varreduras e auditorias em lote, com escopo fechado e olho no consumo. Comece pequeno.
Usar o controle de esforço para casar custo e tarefa. Triagem no baixo, mérito no alto. Simples e imediato.
Não terceirizar a conferência. O 4.8 erra menos e avisa mais — mas “avisa mais” não é “nunca erra”. A responsabilidade pela validação jurídica continua sendo nossa. A máquina aponta a incerteza; quem decide é o servidor e o magistrado.
A tese de sempre continua valendo: o valor não está em ter “a IA mais inteligente”, e sim em construir a ponte entre essa inteligência e os dados judiciais — com governança, custo controlado e verificação humana no fim da linha. O Opus 4.8 só torna essa ponte um pouco mais segura de atravessar.
Fontes
Anthropic — Introducing Claude Opus 4.8 (28/05/2026): https://www.anthropic.com/news/claude-opus-4-8
Claude — Introducing dynamic workflows in Claude Code (28/05/2026): https://claude.com/blog/introducing-dynamic-workflows-in-claude-code
Documentação técnica de workflows: https://code.claude.com/docs/en/workflows (publicada hoje; pode levar algumas horas para indexar)
Escrito em 28 de maio de 2026.