
RAG (Retrieval-Augmented Generation): Potencializando a Criação de Documentos Judiciais com IA

Introdução
O RAG (Retrieval-Augmented Generation) é uma técnica avançada de inteligência artificial que combina a capacidade de recuperação de informações com a geração de texto. Em termos simples, o RAG permite que modelos de IA “consultem” uma base de conhecimento externa antes de formular respostas, resultando em conteúdo mais preciso, confiável e contextualizado.
Para ambientes judiciais como tribunais, o RAG representa uma ferramenta poderosa para a geração de documentos jurídicos padronizados, automatizando a criação de textos que seguem precedentes estabelecidos e modelos institucionais.
Como Funciona o RAG: Componentes Básicos
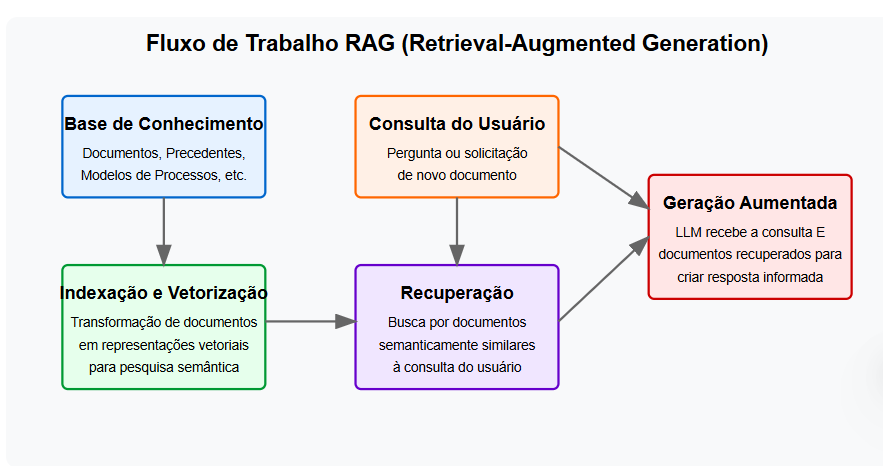
O RAG é composto por três componentes principais, que trabalham em conjunto:
1. Recuperação (Retrieval)
A fase de recuperação envolve a busca de informações relevantes em uma base de conhecimento. Essa base pode conter documentos jurídicos, acórdãos, sentenças anteriores, ou quaisquer outros textos que sirvam como referência para a geração do novo conteúdo.
Diferente de uma busca tradicional por palavras-chave, o RAG utiliza a similaridade semântica, ou seja, ele busca documentos que compartilham significado com a consulta, mesmo que não usem exatamente as mesmas palavras.
2. Aumento (Augmentation)
Nesta etapa, as informações recuperadas na fase anterior são organizadas e incorporadas ao contexto do modelo de linguagem. O modelo tem acesso a estas informações como “material de referência” que deve ser considerado na elaboração da resposta.
3. Geração (Generation)
Por fim, um modelo de linguagem de grande porte (LLM) gera o texto final, levando em consideração tanto a consulta original quanto as informações recuperadas na primeira etapa. O modelo consegue assim criar conteúdo que combina sua capacidade de geração de texto com informações factuais precisas da base de conhecimento.
Conceitos Técnicos Essenciais
Para compreender melhor como o RAG funciona nos bastidores, é importante conhecer alguns conceitos técnicos:
Embeddings e Vetorização
Embeddings são representações numéricas (vetores) de textos que capturam o significado semântico do conteúdo. Para criar a base de conhecimento do RAG, os documentos são transformados em vetores através de modelos de embedding.
Por exemplo, um documento sobre “recurso de apelação” seria convertido em um vetor de números (como [0.12, -0.45, 0.78…]) que representa seu conteúdo semântico em um espaço multidimensional.
Bancos de Dados Vetoriais
Os vetores gerados são armazenados em bancos de dados especializados chamados “bancos de dados vetoriais”. Estes são otimizados para realizar buscas rápidas por similaridade em grandes conjuntos de vetores.
Exemplos de bancos de dados vetoriais incluem Pinecone, Weaviate, Qdrant e FAISS, cada um com suas próprias características e vantagens.
Similaridade Semântica: Como Funciona de Verdade?
A similaridade semântica é como um “DNA” digital de cada texto. Vamos entender isso de forma mais clara:
O Que São Vetores e Como Representam Textos?
Imagine que cada palavra ou documento possui um “DNA” numérico. Este DNA não é formado por letras como A, C, G e T, mas por números. Por exemplo, a palavra “recurso” poderia ter um “DNA” como [0.2, -0.5, 0.7, 0.1], enquanto “processo” poderia ser [0.3, -0.4, 0.6, 0.2].
Estes números capturam o significado da palavra ou documento. Palavras com significados semelhantes terão “DNAs” (vetores) parecidos.
Entendendo a Distância Entre Vetores com Um Exemplo Prático
Imagine que cada documento do seu tribunal está localizado em um ponto específico de uma cidade. Documentos sobre temas similares estão geograficamente próximos uns dos outros:
Todos os modelos de “habeas corpus” estão próximos ao parque central
Todos os modelos de “recursos de apelação” estão próximos ao shopping
Todos os modelos de “sentenças criminais” estão próximos à estação de trem
Quando você faz uma nova consulta, como “preciso de um modelo para habeas corpus preventivo”, é como se você colocasse um alfinete neste mapa. O sistema então mede as distâncias entre o seu alfinete e todos os documentos no mapa, e retorna os que estão mais próximos fisicamente.
Um Exemplo Concreto em Tribunais
Suponha que temos estes documentos na base:
Documento A: “Modelo de despacho para suspensão de execução fiscal por parcelamento”
Documento B: “Modelo de sentença para procedência de embargos à execução fiscal”
Documento C: “Modelo de decisão sobre sobrestamento temporário de processo executivo por adesão ao REFIS”
Quando um juiz busca “suspensão de execução por parcelamento”, o sistema pode identificar que os Documentos A e C são semanticamente mais próximos, mesmo que o Documento C use termos diferentes (“sobrestamento” e “REFIS”), pois o significado subjacente é similar.
Por Que Isso é Melhor que Busca por Palavras-Chave
Uma busca tradicional por palavras-chave encontraria apenas documentos que contêm exatamente as palavras “suspensão”, “execução” e “parcelamento”. Já a busca semântica entende o significado e encontra documentos relevantes mesmo quando usam terminologia diferente.
É como se, em vez de procurar apenas pela aparência física de uma pessoa (características superficiais), você buscasse por sua personalidade e valores (significado profundo).
Contextualização de LLMs
Os Modelos de Linguagem de Grande Porte (LLMs) têm uma capacidade limitada de processar texto (conhecida como “janela de contexto”). O RAG otimiza essa janela de contexto fornecendo apenas as informações mais relevantes para a tarefa em questão.
Aplicação em Tribunais e Ambientes Jurídicos
No contexto de tribunais e órgãos jurídicos, o RAG pode ser implementado para:
Automatizar a geração de documentos padronizados: Acórdãos, despachos e outros documentos que seguem estruturas definidas podem ser gerados automaticamente com base em precedentes.
Manter a consistência institucional: Ao recuperar documentos anteriores da mesma instituição, o RAG garante que novos textos mantenham o estilo e as diretrizes internas.
Acelerar processos: Reduz o tempo necessário para redigir documentos complexos, permitindo que os operadores do direito foquem em análises mais críticas.
Suporte à decisão: Pode apresentar precedentes relevantes para auxiliar na tomada de decisões judiciais.
Passos para Implementação
A implementação de um sistema RAG para unidades de tribunais envolve:
Coleta e preparação de documentos: Reunir os modelos e documentos existentes que servirão como base.
Pré-processamento: Limpeza e normalização dos documentos (remoção de formatação inconsistente, correção de erros, etc.).
Vetorização: Transformação dos documentos em embeddings usando modelos como o da OpenAI, Cohere, ou alternativas abertas como o BERT.
Indexação: Armazenamento dos vetores em um banco de dados vetorial.
Configuração da interface: Desenvolvimento de um sistema que permita aos usuários fazer consultas e especificar o tipo de documento a ser gerado.
Integração com LLM: Configuração de um modelo de linguagem que usará as informações recuperadas para gerar o texto final.
Validação e ajustes: Testes com usuários reais para refinamento do sistema.
Como Funciona na Prática com Documentos Jurídicos
Vamos ver como o RAG funciona em um caso real de um tribunal:
Transformação em vetores: Quando você cadastra um modelo de documento judicial no sistema, ele é transformado em um vetor (uma lista de números) que representa seu significado completo.
Consulta do usuário: Um juiz digita: “Preciso de um modelo de decisão para suspensão de execução fiscal por parcelamento”.
Vetorização da consulta: Esta consulta também é transformada em um vetor.
Cálculo de similaridade: O sistema calcula quão “próximo” este vetor está de todos os outros documentos na base.
Recuperação dos mais similares: Os documentos cujos vetores são mais próximos ao da consulta são recuperados, mesmo que usem palavras diferentes como “sobrestamento” em vez de “suspensão”.
Geração do novo documento: O LLM utiliza os documentos recuperados como referência para criar um novo documento que mantém o estilo e formato dos precedentes, mas adaptado para o caso específico.
Exemplo de Fluxo RAG para Tribunais
Um servidor do tribunal precisa criar um despacho para um caso específico.
Ele insere os detalhes do caso (tipo de processo, fase atual, etc.) na interface do sistema RAG.
O sistema vetoriza essa consulta e busca despachos similares na base de conhecimento.
Os despachos mais relevantes são recuperados e enviados junto com a consulta para o LLM.
O LLM gera um novo despacho que segue o formato e estilo institucional, incorporando elementos dos precedentes recuperados.
O servidor revisa o documento gerado, faz ajustes necessários e o finaliza.
Vantagens e Considerações
Vantagens
Precisão aumentada: Os documentos gerados contêm informações factuais corretas, extraídas da base de conhecimento.
Redução de alucinações: O LLM é “ancorado” em documentos reais, diminuindo a tendência de inventar informações.
Atualização simplificada: A base de conhecimento pode ser facilmente atualizada com novos precedentes ou diretrizes.
Adaptabilidade: O sistema pode ser ajustado para diferentes tipos de documentos e necessidades específicas.
Considerações Importantes
Qualidade da base de conhecimento: O desempenho do RAG depende diretamente da qualidade e abrangência dos documentos indexados.
Segurança e privacidade: Informações sensíveis precisam ser tratadas com os devidos cuidados, especialmente em ambientes jurídicos.
Supervisão humana: Ainda é necessária revisão por profissionais qualificados, especialmente para documentos com implicações legais significativas.
Capacitação: Os usuários precisam ser treinados para formular consultas efetivas que resultem em documentos adequados.
Conclusão
O RAG representa uma evolução significativa na aplicação de inteligência artificial para ambientes jurídicos. Ao combinar a capacidade generativa dos LLMs com a precisão factual de uma base de conhecimento estruturada, o RAG possibilita a automação da criação de documentos mantendo a aderência a precedentes e padrões institucionais.
Para tribunais e outras instituições jurídicas, essa tecnologia oferece ganhos de eficiência e consistência, permitindo que os profissionais do direito dediquem seu tempo a tarefas que requerem expertise humana, enquanto as atividades mais rotineiras de redação podem ser assistidas pela inteligência artificial.
A implementação bem-sucedida de um sistema RAG requer planejamento cuidadoso, desde a preparação da base de conhecimento até a integração com os processos existentes, mas os benefícios potenciais em termos de produtividade e qualidade dos documentos justificam o investimento.